
install.packages("taipan")
Annotating images is tiresome work, and existing tools do not make this much easier. Identifying features within images is a common task for training and evaluating machine learning models, and taipan aims to simplify this very manual process.
What is taipan?
taipan is a Tool for Annotating Images in Preparation for ANalysis. It provides a customisable shiny app that pairs image area selection with a set of shiny inputs to flexibly classify the contents of images. Unlike most shiny app packages, taipan provides functionality to customise the key components (images and questions) of the app, and dynamically builds an app ready for deployment and sharing.
The package originated from a research project with Tennis Australia, where the training dataset of 6406 images of tennis broadcast images were painstakingly annotated by Stephanie Kobakian (@srkobakian). The package is the result of many iterations of the app we created to annotate these images.
Getting started with taipan
The taipan package is now available on CRAN, so it can be easily installed using:
taipan provides two key functions that are used to build your own image annotation app, taipanQuestions is used to build a set of questions, and buildTaipan combines your questions and images to build an app in your folder of choice.
These lists of questions can be flexibly produced using the taipanQuestions function, where any shiny inputs and web elements can be used to build your own survey for ‘scene’ and ‘selection’ scenarios. Scene questions are suitable for questions that apply to the whole image, and are shown when no selection is made. Selection questions are appropriate for selected areas of the image, and are shown when a selection is made.
The questions can then be used to produce the app with buildTaipan, with a set images can be provided using local files and links to images online.
Example: Not hotdog
Suppose we’re interested in training a model to identify hotdogs in an image. To do this, we require a training dataset that describes the location and features of the hotdog.

We would expect a few features that would useful for training the model, such as the existence of a hotdog, condiments of the hotdog, and overall quality of the image. Using shiny, we can construct this question interface using a variety of inputs.
library(taipan)
library(shiny)
questions <- taipanQuestions(
scene = sliderInput(
"quality", label = "Image Quality",
min = 0, max = 10, value = 5),
selection = div(
radioButtons("hotdog", label = "Hotdog?",
choices = list("Hotdog", "Not hotdog")),
checkboxGroupInput("extra", label = "Condiments",
choices = list("Onion", "Tomato (Ketchup)", "Barbeque", "Mustard"))
)
)Next, we need to find a set of questions to use. For this example, I’ve provided two sample images on the package’s GitHub repository.
images <- c("https://raw.githubusercontent.com/srkobakian/taipan/master/sample_images/hotdog.jpg",
"https://raw.githubusercontent.com/srkobakian/taipan/master/sample_images/not_hotdog.jpg")Finally, we can build our app using these questions and images.
buildTaipan(questions, images, appdir = "~/Shiny Applications/nothotdog")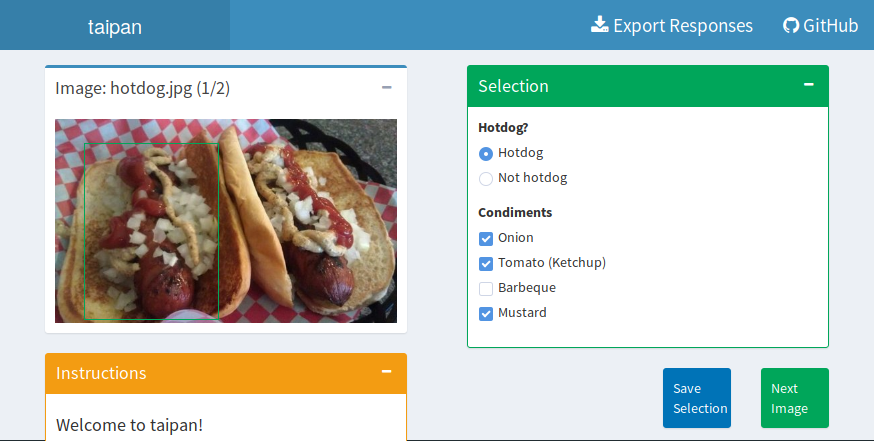
Preview this app at shiny.mitchelloharawild.com/nothotdog/, or run the code to build your own copy.
Once the images have been annotated, the ‘Export Responses’ button can be used to download the data. The data is provided in a long tidy format, where the responses to scene and selection questions are merged and ready for model training and analysis
| image_name | quality | xmin | xmax | ymin | ymax | hotdog | extra |
|---|---|---|---|---|---|---|---|
| hotdog.jpg | 6 | 51 | 249 | 36.5 | 303.5 | Hotdog | Onion, Tomato (Ketchup), Mustard |
| hotdog.jpg | 6 | 272 | 486 | 32.5 | 282.5 | Hotdog | Onion, Tomato (Ketchup), Mustard |
| not_hotdog.jpg | 7 | NA | NA | NA | NA | NA | NA |
Additional resources
- Stephanie’s (@srkobakian) useR!2018 lightning talk
- The vignette which shows annotation of tennis images
- The GitHub repository
Citation
BibTeX citation:
@online{oharawild2018taipan,
author = {O’Hara-Wild, Mitchell},
title = {Introducing Taipan},
date = {2018-09-27},
url = {https://mitchelloharawild.com/blog/taipan/},
langid = {en}
}
For attribution, please cite this work as:
O’Hara-Wild, Mitchell. 2018. “Introducing Taipan.”
September 27, 2018. https://mitchelloharawild.com/blog/taipan/.